
ABSTRAK
Penggunaan sistem panel surya fotovoltaik (PV), sebagai sumber energi terbarukan, telah mengalami peningkatan akhir-akhir ini. Oleh karena itu, sangat penting untuk menerapkan metode yang efisien untuk mendeteksi dan mendiagnosis kesalahan sistem PV secara akurat guna mencegah gangguan daya yang tidak terduga. Makalah ini memperkenalkan strategi potensial untuk identifikasi dan klasifikasi kesalahan melalui pemanfaatan teknik pembelajaran mesin (ML). Penelitian ini bertujuan untuk menggunakan algoritma ML guna mengidentifikasi dan mengklasifikasikan operasi normal, tujuh jenis kesalahan yang berbeda, dalam dua mode operasional (pelacakan titik daya maksimum dan pelacakan titik daya menengah). Empat algoritma pembelajaran mesin dan metode ensembel (pohon keputusan, k-tetangga terdekat, hutan acak, dan peningkatan gradien ekstrem) digunakan, diikuti oleh penyetelan hiperparameter dan validasi silang untuk menentukan konfigurasi terbaik. Hasilnya menunjukkan bahwa metode ensembel, khususnya XGBoost, unggul dalam mendeteksi dan mengklasifikasikan kesalahan dalam sistem PV, mencapai tingkat akurasi 99% setelah penyesuaian hiperparameter. Nilai TPR menunjukkan sensitivitas tinggi sebesar 0,999, dengan beberapa mencapai skor sempurna sebesar 1.000. FPR menunjukkan nilai yang sangat rendah, dengan mayoritas metrik menunjukkan FPR pada atau mendekati 0%. Performa ini sangat penting dalam konteks energi surya, karena kegagalan dalam mendeteksi kesalahan dapat mengakibatkan hilangnya energi secara signifikan dan peningkatan biaya perawatan.
1 Pendahuluan
Selama dekade terakhir, telah terjadi peningkatan substansial dalam penggunaan listrik global, terutama didorong oleh revolusi teknologi. Dalam masyarakat kontemporer, peralatan elektronik dan sistem kelistrikan telah menjadi elemen yang sangat diperlukan dalam kehidupan manusia. Banyak aktivitas penting yang terkait dengan kenyamanan manusia tidak akan mungkin dilakukan tanpa bantuan energi listrik. Selain itu, peningkatan populasi global, ditambah dengan munculnya kota pintar dan munculnya Industri 4.0, akan mengakibatkan lonjakan substansial dalam permintaan daya listrik. Tiga sumber energi utama yang digunakan untuk pembangkitan listrik adalah tenaga nuklir, energi terbarukan, dan bahan bakar fosil (termasuk batu bara, gas alam, dan minyak bumi). Turbin uap, yang berbahan bakar bahan bakar fosil, tenaga nuklir, biomassa, atau energi panas bumi, menghasilkan sebagian besar listrik di seluruh dunia. Dalam beberapa dekade terakhir, beberapa negara, termasuk AS, Tiongkok, dan Eropa, telah mengadopsi teknologi energi terbarukan sebagai pengganti pembangkitan listrik. Panel fotovoltaik (PV) adalah sistem energi terbarukan yang paling banyak digunakan [ 1 ].
Namun, sistem ini dapat mengalami banyak malfungsi yang dapat menurunkan daya keluarannya. International Energy Outlook 2013 dari Badan Informasi Energi AS memproyeksikan bahwa sistem surya yang terhubung ke jaringan akan menghasilkan 452 miliar kWh daya di seluruh dunia pada tahun 2040, naik dari 34 miliar kWh pada tahun 2010. Salah satu keuntungan utama penerapan sistem fotovoltaik (PV) adalah tingkat aksesibilitas yang tinggi terhadap energi surya. Lebih jauh lagi, sistem ini melepaskan sedikit karbon dioksida dan merupakan sumber energi yang berkelanjutan. Namun, kerugian dari sistem PV meliputi biaya awal yang tinggi, kerentanan terhadap kesalahan, ketidakpastian, dan masalah ketergantungan [ 2 , 3 ].
Sumber energi terbarukan, bila dipadukan dengan jaringan daya menengah atau rendah, akan memberikan tekanan berlebihan pada jaringan transmisi daya, yang menyebabkan kualitas daya menurun, profil tegangan tidak menguntungkan, dan kerugian meningkat [ 4 ]. Selain itu, sistem fotovoltaik dapat mengalami masalah karena masalah listrik, lingkungan, atau fisik [ 5 ]. Oleh karena itu, sistem deteksi cacat yang andal sangat penting untuk meningkatkan pemantauan sistem fotovoltaik [ 6 ].
Daya listrik berkualitas rendah memiliki dampak signifikan pada kenyamanan manusia, proses manufaktur, dan sistem keuangan [ 7 , 8 ]. Deteksi kesalahan sangat penting untuk memastikan keandalan sistem dan mencegah pemadaman parah yang tidak direncanakan [ 9 , 10 ]. Kemajuan dalam otomatisasi, prediksi, dan manajemen telah memungkinkan metode deteksi kesalahan yang canggih untuk meningkatkan keandalan dan ketersediaan sistem. Makalah ini menekankan peran penting yang dapat dimainkan oleh Machine Learning (ML) dalam deteksi kesalahan dan pencegahan pemadaman. Studi ini juga menggabungkan kemampuan belajar mandiri dalam sistem, menambahkan aspek inovatif pada penelitian. Sementara literatur yang ada telah membahas identifikasi dan kategorisasi kesalahan dalam sistem fotovoltaik (PV), masih ada kesenjangan dalam memahami dampak pelatihan mandiri ML dalam meningkatkan sistem prediksi.
Makalah ini bertujuan untuk mengatasi keterbatasan yang diidentifikasi dalam literatur tentang deteksi kesalahan dalam sistem fotovoltaik (PV). Keterbatasan ini meliputi fokus yang sempit pada sejumlah kecil jenis kesalahan, kompleksitas model yang ada yang menghambat implementasi waktu nyata, dan pertimbangan yang tidak memadai terhadap variabilitas lingkungan. Untuk mengatasi masalah ini, model pembelajaran mesin baru akan disajikan. Model ini dapat secara akurat mengidentifikasi dan mengkategorikan cacat dengan menganalisis berbagai jenis kesalahan dan menggunakan data listrik dan tegangan untuk mendeteksi 16 mode operasional, termasuk kondisi normal dan salah. Lebih jauh, model ini menyarankan fine-tuning hiperparameter yang optimal dan memvalidasi sistem yang diusulkan melalui data eksperimen. Khususnya, model ini memperkenalkan diagram klasifikasi deteksi kesalahan, sebuah fitur yang tidak digunakan dalam karya yang diterbitkan sebelumnya, memastikan bahwa teknik yang digunakan mudah dipahami dan dapat ditafsirkan.
Makalah ini terdiri dari enam bagian utama: Bagian 2 akan memberikan ringkasan dari karya-karya yang ada dan menyoroti kesenjangan penelitian. Bagian 3 akan membahas sistem PV surya yang digunakan dalam penelitian ini dan jenis-jenis kesalahan yang dipertimbangkan. Bagian 4 akan menjelaskan metodologi pendekatan yang diusulkan. Bagian 5 akan menyajikan dan membahas hasilnya. Terakhir, Bagian 6 akan menyimpulkan makalah ini.
2 Sastra
Kemajuan teknologi terkini telah memungkinkan untuk mengidentifikasi cacat pada sistem fotovoltaik menggunakan metode seperti kecerdasan buatan, ML, Pembelajaran Mendalam (DL), dan Internet of Things. Metodologi saat ini dapat dibagi menjadi dua kategori: Yang pertama mengidentifikasi cacat fotovoltaik (PV), sedangkan yang kedua mengkategorikan jenis kesalahan spesifik dalam sistem fotovoltaik (PV). Literatur telah mengusulkan berbagai saran untuk identifikasi kesalahan. Misalnya, Drews et al. [ 11 ] memperkenalkan metode deteksi kesalahan yang mengandalkan data satelit. Metode ini mungkin dibatasi oleh ketergantungannya pada sumber data eksternal, yang dapat memengaruhi keakuratan deteksi kesalahan dalam situasi tertentu di mana data satelit tidak dapat diandalkan. Tsanakas et al. [ 12 ] menyarankan metode untuk mendeteksi kesalahan dalam modul PV dengan menggunakan gambar termal bersama dengan detektor tepi canny. Sementara pendekatan ini menyoroti pentingnya investigasi termal, pendekatan ini mungkin menghadapi tantangan dengan positif palsu dalam kondisi lingkungan yang berbeda.
Garoudja et al. [ 13 ] merinci pengembangan teknik statistik untuk mengidentifikasi dan mendeteksi kegagalan dalam sistem fotovoltaik (PV). Tujuan utama penelitian mereka adalah untuk segera mendeteksi dan mengidentifikasi masalah yang terjadi pada sisi DC sistem surya, seperti gangguan naungan parsial, gangguan sirkuit terbuka, dan gangguan sirkuit pendek. Penekanan pada deteksi cepat sangat berharga; namun, metode statistik mungkin tidak secara efektif menangkap dinamika gangguan yang kompleks. Rodrigues et al. [ 14 ] memperkenalkan model nonlinier yang menggunakan pemodelan kotak hitam dari Identifikasi Sistem. Mereka memilih struktur model Hammerstein–Wiener karena kemampuannya untuk secara akurat mewakili nonlinier panel PV dengan jelas dan langsung. Sinyal masukan model yang diusulkan terdiri dari suhu dan iradiasi panel PV. Sementara model ini secara efektif mewakili nonlinier PV, kompleksitasnya mungkin menimbulkan tantangan untuk implementasi waktu nyata.
Rakesh et al. [ 15 ] mengusulkan sebuah metodologi untuk mendeteksi cacat pada susunan PV melalui sebuah proses dua langkah. Awalnya, variabel-variabel dimodifikasi untuk secara akurat menentukan sifat cacat. Berikutnya, jumlah aktual dioda pemblokiran rangkaian terbuka dan dioda bypass rangkaian pendek dibandingkan dengan nilai-nilai prediksi berdasarkan kurva karakteristik IV susunan PV pada gangguan Line-Line. Meskipun model ini secara efektif mewakili nonlinieritas PV, kompleksitasnya mungkin menimbulkan tantangan untuk implementasi waktu nyata. Aboshady dan Taha [ 16 ] menyajikan sebuah pendekatan yang cepat dan ekonomis untuk mengidentifikasi dan mengkategorikan malfungsi dalam sistem PV. Metode ini bergantung pada analisis laju perubahan daya terukur pada level susunan untuk mendeteksi masalah bayangan dan hubung singkat. Sistem ini berhasil mengidentifikasi dan mengkategorikan berbagai macam gangguan, seperti gangguan intra-string dan cross-string, dengan hanya menggunakan dua transduser arus untuk setiap dua string. Meskipun efektif dalam mengkategorikan berbagai kesalahan, metode ini mungkin mengabaikan masalah-masalah kecil yang tidak mengubah tingkat daya secara signifikan.
Selain itu, Et-taleby et al. [ 17 ] memperkenalkan pendekatan baru menggunakan kombinasi CNN dan SVM untuk mengidentifikasi dan mengkategorikan cacat pada gambar elektroluminesensi (EL) panel PV. Model yang diusulkan menjalani pelatihan dan evaluasi menggunakan dua basis data, yang terdiri dari gambar elektroluminesensi sel PV. Kumpulan data berisi foto-foto elektroluminesensi yang diambil dengan kamera EL yang menghadap ke depan. Sel PV dapat menunjukkan berbagai cacat yang dapat ditemukan. Kualitas sambungan listriknya dapat dinilai menggunakan teknologi efisien yang dikenal sebagai pencitraan EL. Pendekatan mereka menunjukkan potensi pembelajaran mendalam dalam klasifikasi kesalahan, tetapi sangat bergantung pada data gambar berkualitas tinggi, yang mungkin tidak selalu dapat diakses.
Konteks klasifikasi kesalahan telah menyajikan berbagai metodologi kontemporer. Penulis studi [ 18 ] menyajikan sistem pemantauan yang mengumpulkan data tentang variabel lingkungan dan listrik. Sistem ini memungkinkan penyelidikan parameter efisiensi pabrik menggunakan data historis dan waktu nyata. Mereka mengusulkan model linier rekursif menggunakan MS untuk mendeteksi kesalahan sistem. Outputnya adalah daya, sedangkan sinyal inputnya adalah suhu dan iradiasi pada panel PV. Keterbatasan pekerjaan ini dapat diringkas oleh fakta bahwa hanya sejumlah kecil kesalahan yang dipertimbangkan selama pengujian pendekatan yang diusulkan. Hal ini menimbulkan pertanyaan tentang generalisasi pendekatan yang diusulkan di berbagai lingkungan. Memon et al. [ 6 ] melakukan studi yang menyajikan pendekatan lanjutan untuk mendeteksi cacat pada panel fotovoltaik (PV). Model yang disarankan melatih CNN menggunakan data historis. CNN menerima iterasi praproses dari kumpulan data. Kumpulan data memiliki berbagai pengukuran untuk masing-masing dari lima kategori, termasuk arus, tegangan, suhu, dan iradiasi. Meskipun model menunjukkan akurasi yang tinggi, penting untuk dicatat bahwa hanya empat jenis kesalahan yang dipertimbangkan. Hal ini mengarah pada diskusi tentang apakah metode yang diusulkan berguna dalam aplikasi di dunia nyata.
Zaki et al. [ 19 ] menyajikan metode baru untuk klasifikasi gangguan pada sistem PV menggunakan CNN pembelajaran mendalam yang canggih. Strategi ini memanfaatkan ekstraksi fitur otomatis untuk mengurangi beban komputasi dan meningkatkan akurasi klasifikasi. Mereka memvalidasi model CNN secara teoritis dan praktis menggunakan pemilihan kejadian gangguan normal dan enam kejadian gangguan, yang dipilih berdasarkan kondisi atmosfer yang berbeda. Mereka secara bersamaan menganalisis dan memilih tiga indikator listrik sebagai masukan untuk model klasifikasi yang diusulkan. Hasilnya menunjukkan akurasi deteksi yang tinggi. Namun, hanya enam mode gangguan yang dipertimbangkan.
Dalam penelitian mereka, Badr et al. [ 20 ] memperkenalkan kerangka kerja ML yang sangat cocok untuk mendiagnosis dan mendeteksi gangguan umum secara otomatis dalam susunan PV. Gangguan ini mencakup masalah sementara seperti shading dan gangguan permanen seperti gangguan busur, gangguan line-to-line, kegagalan pada unit pelacakan titik daya maksimum, dan gangguan sirkuit terbuka. Mereka merancang kerangka kerja untuk menangani berbagai skenario shading, impedansi gangguan, dan kumpulan data iklim. Penelitian ini mengamati tiga pengklasifikasi ML dan mencoba menemukan yang terbaik. Pengklasifikasi tersebut adalah pohon keputusan dengan kriteria pemisahan yang berbeda, k-nearest neighbor dengan metrik jarak dan fungsi pembobotan yang berbeda, dan support vector machines (SVM) dengan fungsi kernel dan teknik multiklasifikasi yang berbeda. Mereka menggunakan optimasi Bayesian untuk mengidentifikasi hiperparameter ideal untuk klasifikasi gangguan. Meskipun mencapai akurasi yang tinggi, model tersebut hanya mempertimbangkan 11 jenis gangguan dan menggunakan tiga jenis model ML (SVM, DT, dan KNN). Oleh karena itu, penting untuk menguji kinerja algoritma ML lainnya, seperti pembelajaran ensemble dan teknik pembelajaran mendalam.
Chokr et al. [ 21 ] mengusulkan penggunaan metodologi ML yang diawasi untuk meningkatkan deteksi dan diagnosis kesalahan. Metode ini menggunakan Strategi Pengurangan Dimensi Data yang mengintegrasikan mekanisme penentuan ambang batas yang sesuai untuk skor Penguatan Informasi dengan Analisis Komponen Utama. Meskipun model tersebut menunjukkan akurasi yang tinggi, model tersebut dievaluasi untuk tujuh jenis kesalahan, dan tidak ada penyetelan hiperparameter yang dilakukan untuk memilih konfigurasi model ML terbaik. Adhya et al. [ 22 ] menggunakan tiga algoritma ML, termasuk CatBoost, LGBM, dan XGBoost, untuk tujuan mengkategorikan kesalahan dalam susunan PV. Meskipun penelitian ini mencapai akurasi yang tinggi dalam klasifikasi menggunakan LGBM, CatBoost, dan XGBoost, penting untuk dicatat bahwa temuan tersebut didasarkan pada kumpulan data spesifik yang dibangun dari data iradiasi dan suhu waktu nyata dari satu sistem PV. Fokus yang sempit ini dapat membatasi generalisasi hasil, karena kinerja algoritma dapat bervariasi secara signifikan dalam kondisi lingkungan yang berbeda, lokasi geografis, atau dengan jenis sistem PV lainnya. Mustafa et al. [ 23 ] menggunakan jaringan CNN, LSTM, dan Bi-LSTM untuk mendeteksi dan mengklasifikasikan tiga jenis kesalahan kesalahan yang berbeda secara tepat menggunakan jumlah sensor yang berkurang, sehingga menghasilkan pendekatan yang hemat biaya dan efisien. Teknik pemodelan yang dipisahkan memfasilitasi skalabilitas yang ditingkatkan dan pembuatan set data multi-label, sehingga sangat cocok untuk aplikasi skala besar. Teknik pembelajaran mendalam tingkat lanjut, termasuk NN, Memori Jangka Pendek Panjang, dan Memori Jangka Pendek Panjang Dua Arah, diimplementasikan. Salah satu batasan dari penelitian ini adalah, meskipun mencapai akurasi tinggi dalam klasifikasi menggunakan LGBM, CatBoost, dan XGBoost, temuannya didasarkan pada set data spesifik yang dibangun dari data iradiasi dan suhu waktu nyata dari satu sistem PV. Fokus yang sempit ini dapat membatasi generalisasi hasil, karena kinerja algoritme dapat bervariasi secara signifikan dalam kondisi lingkungan yang berbeda, lokasi geografis, atau dengan jenis sistem PV lainnya.
Mellit dan Kalogirou [ 24 ] mengevaluasi berbagai metode ML dan ensemble learning untuk mendeteksi dan mengklasifikasikan kegagalan dalam susunan PV. Penekanan utamanya adalah pada mengidentifikasi dan mengklasifikasikan cacat kompleks, seperti beberapa kesalahan dan kesalahan dengan kurva I–V yang serupa, yang belum pernah dievaluasi sebelumnya, dan yang berpotensi memengaruhi susunan PV. Model ini bagus dalam mendeteksi kesalahan, tetapi mungkin tidak seakurat dalam mengklasifikasikannya, yang dapat menyebabkan kesalahan diagnosis dalam situasi dunia nyata. Selain itu, makalah ini terutama berfokus pada jenis kesalahan tertentu, sehingga temuannya mungkin tidak berlaku untuk kondisi kesalahan lain yang tidak dipelajari. Li et al. [ 25 ] telah membuat metodologi baru yang secara efektif menggunakan data kurva I–V untuk mendiagnosis kesalahan dalam sistem PV. Fitur kesalahan diperoleh dengan mengekstraknya secara langsung dari vektor arus yang diambil sampel ulang atau mengonversi vektor menggunakan medan perbedaan sudut Gramian atau plot rekursif. Mereka menilai enam algoritme ML, yaitu SVM, DT, RF, KNN, dan pengklasifikasi Bayesian naif. Studi tersebut difokuskan pada kemampuan menangani gangguan lingkungan dan kesalahan pengukuran, tetapi pengujian tersebut mungkin tidak mencakup semua kondisi ekstrem atau jenis kesalahan tidak umum yang dapat terjadi dalam kehidupan nyata. Selain itu, penggunaan beberapa teknik ML dalam metodologi tersebut tidak mengatasi risiko overfitting, terutama ketika hanya sejumlah kecil kondisi kesalahan yang dievaluasi.
Amiri et al. [ 26 ] mengusulkan metodologi dua langkah untuk mengembangkan model array fotovoltaik (PV) yang andal dan menerapkan sistem deteksi kesalahan menggunakan Random Forest Classifiers (RFC). Pendekatan ini melibatkan ekstraksi lima parameter yang tidak diketahui dari model satu-dioda (ODM) melalui algoritma optimasi serigala abu-abu yang dimodifikasi dan simulasi array PV untuk mendapatkan koordinat titik daya maksimum (MPP). Hasilnya menunjukkan validasi yang kuat dari teknik pemodelan, mencapai root mean square error (RMSE) sebesar 0,0122 untuk ekstraksi parameter dan RMSE di bawah 0,3 dalam simulasi dinamis dalam kondisi berawan. RFC menunjukkan tingkat akurasi klasifikasi yang tinggi sebesar 99,4% untuk deteksi dan diagnosis kesalahan, mengungguli beberapa model ML lainnya. Namun, ketergantungan penelitian pada algoritma yang kompleks, kendala lingkungan, dan model dioda tunggal dapat membatasi generalisasi dan penerapan praktisnya, serta menimbulkan pertanyaan tentang kekokohan kinerja komparatifnya.
Hichri et al. [ 27 ] memperkenalkan metode pemilihan fitur yang dikenal sebagai algoritma salp swarm (SSA) untuk meningkatkan akurasi klasifikasi pengklasifikasi supervised ML (SML) dengan mengidentifikasi dan mempertahankan hanya fitur yang paling signifikan dari data mentah sambil membuang yang tidak perlu. Fitur yang dipilih kemudian digunakan untuk melatih model SML untuk membedakan antara berbagai mode operasi dalam sistem fotovoltaik yang terhubung ke jaringan (GCPV), yang mengalami kesalahan yang sering terjadi, termasuk 20 jenis yang berbeda seperti kesalahan line-to-line dan line-to-ground, bersama dengan masalah konektivitas dan dioda bay-pass. Kinerja metode SSA-SML dievaluasi terhadap teknik tradisional seperti analisis komponen utama (PCA) dan kernel PCA (KPCA), dengan mengukur kriteria seperti akurasi, recall, presisi, skor F1, dan waktu komputasi. Hasilnya menunjukkan bahwa metode SSA-SML mencapai akurasi diagnostik yang luar biasa (lebih dari 99%) dan mengurangi waktu komputasi secara signifikan dibandingkan dengan teknik lain. Namun, keterbatasan penelitian ini terletak pada ketergantungannya pada jenis kesalahan dan kumpulan data tertentu, yang dapat membatasi generalisasi temuan ke berbagai skenario dunia nyata dan variasi dalam sistem GCPV.
Berdasarkan tinjauan pustaka di atas, keterbatasan berikut dapat diidentifikasi:
1.Jenis Kesalahan Terbatas: Banyak penelitian berfokus pada rentang jenis kesalahan yang sempit, sering kali hanya menilai enam hingga 11 kesalahan tertentu. Cakupan terbatas ini menimbulkan kekhawatiran tentang penerapan dan efektivitas model dalam mendiagnosis skenario kesalahan yang kurang umum atau rumit yang mungkin muncul dalam sistem PV di dunia nyata.
2.Kompleksitas Model: Model tertentu, seperti model Hammerstein-Wiener dan berbagai teknik pembelajaran mendalam, mungkin terlalu rumit untuk diterapkan secara langsung dalam situasi praktis. Diperlukan model yang lebih sederhana, lebih mudah ditafsirkan, dan tetap memiliki akurasi tinggi.
3.Variabilitas Lingkungan: Banyak penelitian tidak secara memadai membahas dampak dari berbagai kondisi lingkungan terhadap deteksi dan klasifikasi kesalahan. Kinerja dapat berbeda secara signifikan dalam berbagai iklim atau konteks operasional, yang belum dieksplorasi secara memadai dalam penelitian yang ada.
Oleh karena itu, penelitian ini bertujuan untuk mengembangkan model ML sederhana berdasarkan data listrik dan tegangan untuk mendeteksi 16 mode (normal dan gangguan). Selain itu, teknik ML yang digunakan dalam penelitian ini sederhana untuk menghindari kompleksitas sistem yang ada.
3 Sistem Fotovoltaik yang Digunakan
Seperti yang disarankan oleh Bakdi et al. [ 28 ], penelitian ini mengevaluasi efektivitas Fault Detection and Classification (FDC) dengan membandingkannya dengan kegagalan aktual dalam mode MPPT dan IPPT menggunakan sistem PV yang terhubung ke jaringan. Gambar 1 menggambarkan pemasangan sistem PV yang terhubung ke jaringan [ 29 ].
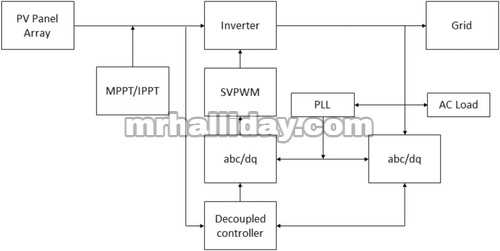
GAMBAR 1
Emulator susunan surya Chroma 62150H-1000S adalah perangkat yang dapat diprogram yang menghasilkan output dari susunan fotovoltaik (PV) dan dapat mensimulasikan berbagai kondisi iklim. Gomathi dan Ramachandran [ 29 ] menggunakan sumber AC yang dapat diprogram Chroma 61511 sebagai emulator jaringan. Mereka melakukan akuisisi data dalam lingkungan DSpace 1104, di mana pekerjaan mereka juga mengembangkan algoritma kontrol dan mengintegrasikan teknologi kontrol berorientasi tegangan dengan modulasi lebar pulsa vektor ruang untuk mengatur daya aktif dan reaktif menggunakan data sisi jaringan. Loop kunci fase menyinkronkan tegangan output dengan tegangan jaringan. Pengontrol sistem menggunakan teknik Particle Swarm Optimization untuk mencapai MPPT ketika level daya yang tersedia di bawah atau sama dengan daya terukur (a ≤), dan mode IPPT ketika level daya yang tersedia lebih besar dari daya terukur (a >). Untuk mendapatkan detail tambahan mengenai sistem kontrol, sistem manajemen energi, komunikasi, dan pengaturan sistem ini, individu yang tertarik dapat merujuk ke Bakdi et al. [ 28 ]. Sistem ini menghasilkan dan mengumpulkan data keliru yang autentik untuk verifikasi eksperimental deteksi kesalahan daring secara langsung.
3.1 Jenis Kesalahan
Investigasi dalam makalah ini melibatkan pengenalan cacat nyata secara sengaja, sementara beban AC bertindak sebagai tindakan perlindungan. Para peneliti mempertimbangkan total tujuh kesalahan yang masuk akal dalam sistem ini (lihat Tabel 1 ).
| Kesalahan | Jenis | Keterangan |
|---|---|---|
| Bahasa Indonesia: F1 | Pengubah arus | Kegagalan Total pada satu dari enam IGBT |
| F2 | Sensor umpan balik | 20% kesalahan sensor satu fase |
| F3 | Anomali jaringan | Penurunan tegangan intermiten |
| F4 | Ketidakcocokan susunan PV | 10 hingga 20% naungan parsial non-homogen |
| F5 | Ketidakcocokan susunan PV | 15% sirkuit terbuka dalam susunan PV |
| F6 | Pengontrol MPPT/IPPT | -20% parameter penguatan pengontrol PI di pengontrol MPPT/IPPT dari konverter penguat |
| F7 | Pengontrol konverter boost | +20% dalam parameter konstanta waktu pengontrol PI di pengontrol MPPT/IPPT dari konverter boost |
Cacat-cacat ini muncul dalam berbagai bentuk dan terletak di area yang berbeda untuk memudahkan evaluasi menyeluruh. Mereka sengaja membuat setiap kesalahan dalam serangkaian percobaan yang berurutan dan independen. Mereka melakukan percobaan secara berurutan pada interval 10 hingga 15 detik. Masalah muncul antara detik ke-7 dan ke-8. Waktu sampel untuk pengumpulan data yang bebas kesalahan dan cacat adalahaku
Tidak seperti studi simulasi, stempel waktu pasti terjadinya kegagalan algoritma tidak pasti. Mengidentifikasi ketidaksesuaian susunan PV seperti F4 dan F5 merupakan tantangan karena variabilitas yang signifikan dalam data sensor sisi DC.
Untungnya, cacat ini memiliki tingkat keparahan yang lebih rendah dan hanya mengakibatkan kerugian daya. Karena cacat ini hanya mempengaruhi sisi AC dari sistem PV yang terhubung ke jaringan, di mana data menunjukkan variabilitas minimal, kesalahan F1 dan F3 pada sisi jaringan dapat dengan mudah dideteksi. Meskipun demikian, sangat penting untuk mengidentifikasi cacat ini pada fase pertama dalam jangka waktu yang terbatas untuk deteksi kesalahan. Beberapa kesalahan pada pengontrol Proportional Integral (PI) MPPT/IPPT pada sisi DC juga diperiksa oleh sistem ini. Sistem ini juga memeriksa masalah pada sensor arus umpan balik (F2). Kode kesalahan pengontrol F7 menunjukkan parameter konstanta waktu yang tinggi, sedangkan kode kesalahan pengontrol PI F6 menunjukkan penguatan yang bias. Penguatan yang bias ini menyebabkan kinerja yang berkurang dalam melacak lintasan titik daya maksimum (MPPT/IPPT) tetapi tidak memengaruhi stabilitas sistem loop tertutup.
3.2 Deskripsi File Data
Dataset yang digunakan dalam penelitian ini diperoleh dari Bakdi et al. [ 28 ]. Komposisi terdiri dari 16 file, masing-masing diberi label
, Di mana:
4 Metodologi
Tujuan utama dari pekerjaan ini adalah untuk mengembangkan metodologi berbasis ML untuk mengidentifikasi dan mengklasifikasikan kesalahan dalam sistem fotovoltaik. Metode yang diusulkan, yang dikenal sebagai Fault Detection and Classification (FDC), tidak terpengaruh oleh kondisi lingkungan karena metode ini bergantung pada parameter arus dan tegangan sistem PV surya. Selain itu, metode ini sederhana dan dapat diimplementasikan secara real-time menggunakan teknik ML dasar daripada algoritma jaringan saraf. Metode ini juga serbaguna, karena dapat secara efektif mendeteksi 16 mode sistem PV surya yang berbeda.
ML adalah subdivisi dari kecerdasan buatan (AI) yang membangun model menggunakan data sampel untuk membuat prediksi otonom tanpa memerlukan campur tangan manusia atau formula yang telah ditetapkan sebelumnya. Ada dua kategori utama algoritma ML: diawasi dan tidak diawasi, seperti yang diidentifikasi oleh El Samad et al. [ 30 ]. Studi ini akan menggunakan algoritma ML yang diawasi karena input dan output yang diketahui untuk algoritma ML tersedia. Gambar 2 menggambarkan representasi skematis dari pendekatan FDC. Penting untuk menyoroti bahwa diagram yang disajikan dalam makalah ini berasal dari pendekatan unik yang dikembangkan dalam studi ini dan tidak ada dalam karya yang diterbitkan sebelumnya. Kontribusi asli ini meningkatkan literatur yang ada secara signifikan.
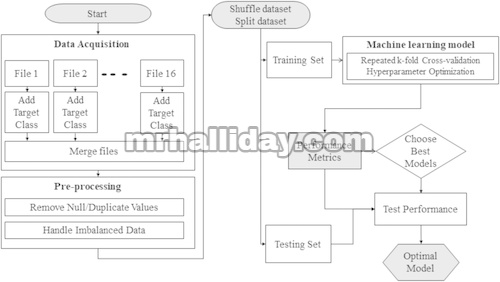
4.1 Akuisisi Dataset
Tahap awal melibatkan pengumpulan data yang relevan, dengan total 16 file yang tersedia dari Bakdi et al. [ 28 ] dan digambarkan dalam Gambar 3 . Setiap file berisi bentuk kerusakan yang khas atau berbeda dalam mode operasi tertentu. Gambar 3 menampilkan bentuk dalam hal jumlah baris dan jumlah kolom setiap file.

Pada Gambar 3 , I melambangkan mode IPPT dan M melambangkan mode MPPT, {0, 1, 2, …, 7} melambangkan tipe normal untuk 0 dan jumlah kesalahan yang diilustrasikan pada Tabel 1 .
Kolom dengan kelas target “label” ditambahkan ke setiap berkas untuk membuat kumpulan data terpadu. Label ini menentukan jenis masalah dan mode fungsionalitas. Selanjutnya, berkas-berkas ini digabungkan untuk membentuk kumpulan data yang berbeda, termasuk 2.163.480 baris dan 16 kolom.
4.2 Pra-Pemrosesan dan Pemisahan Dataset
Kehadiran 16 klasifikasi yang berbeda mendistorsi dataset, seperti yang ditunjukkan Gambar 3. Tahap ini memerlukan penghapusan nilai nol atau duplikat dari dataset menggunakan teknik over-sampling minoritas sintetis (SMOTE); ini mengatasi distribusi kelas yang tidak merata dalam dataset. Dengan mereproduksi contoh secara acak dari kelas minoritas, tujuannya adalah untuk menghasilkan distribusi kelas yang sama. SMOTE menghasilkan contoh minoritas sintetis dengan menggabungkan yang sudah ada. Kelas minoritas menggunakan interpolasi linier untuk menghasilkan data pelatihan virtual. Untuk setiap contoh di kelas minoritas, kami secara acak memilih satu atau lebih tetangga k-terdekat untuk menghasilkan rekaman pelatihan sintetis. Pendekatan oversampling membuat ulang data, yang memungkinkan analisis beberapa model klasifikasi [ 31 ]. Pendekatan SMOTE mendistribusikan dataset secara merata di antara berbagai kelas, dengan setiap kelas berisi 12.9730 baris.
Sebelum membagi dataset, operasi shuffle dilakukan untuk mengacak urutan beberapa kelas target, seperti yang digambarkan pada Gambar 4. Setelah proses shuffle, dataset akan dipartisi menjadi dua set: set pelatihan, yang akan mencakup 75% dari dataset, dan set pengujian, yang akan mencakup 25% dari dataset.

GAMBAR 4
4.3 Model Pembelajaran Mesin
Seperti yang telah disebutkan sebelumnya, model ML berfungsi sebagai komponen dasar dari teknik FDC. Untuk memastikan akurasi klasifikasi tertinggi, sangat penting untuk memilih algoritma ML yang optimal. Dengan demikian, para peneliti dalam makalah ini melatih beberapa model ML untuk menilai kinerjanya, seperti yang diilustrasikan dalam Gambar 2. Ada dua metode yang umum digunakan untuk menilai kinerja model: validasi hold-out dan validasi silang k-fold. Teknik validasi silang k-fold membagi kumpulan data menjadi blok k, atau lipatan, secara bertingkat. Oleh karena itu, jika mewakili besarnya kumpulan data, set pelatihan, dilambangkan sebagai , akan memiliki ukuran yang sama dengan 80% dari total dataset. Selanjutnya, dipartisi menjadi blok. Satu blok berukuran , dialokasikan untuk tujuan validasi. Sisanya Blok ini digunakan untuk melatih model ML untuk k iterasi [ 32 ].
Teknik validasi silang k-fold berulang digunakan untuk mengoptimalkan hiperparameter. Dalam metode ini, validasi silang k-fold diulang kali. Penerapan validasi silang lipatan berulang akan diulang untuk nilai Tiga iterasi validasi silang k-fold akan dijalankan masing-masing pada nilai parameter model yang berbeda. Performa model dihitung untuk setiap iterasi. Nilai parameter terbaik diperoleh dari pengulangan yang menunjukkan performa maksimum.
Empat model ML yang digunakan dalam makalah ini adalah:
Pohon Keputusan (Decision Tree/DT): Ini adalah metode yang ampuh dan efisien untuk tugas pembelajaran terbimbing yang melibatkan klasifikasi dan regresi. Sistem ini menggunakan kerangka diagram alir di mana simpul inti mewakili pengujian; cabang menunjukkan hasil dan simpul daun menentukan nama kelas. Sistem ini membagi data pelatihan menjadi beberapa bagian secara rekursif, menggunakan ukuran seperti entropi setelah persyaratan penghentian terpenuhi [ 33 ].
K-Nearest Neighbors (KNN): Ini adalah algoritma pembelajaran terbimbing yang digunakan dalam bidang pengenalan pola, penambangan data, dan deteksi intrusi. Algoritma memilih
tetangga terdekat dengan mengevaluasi metrik jaraknya dan kemudian menentukan kelas titik data berdasarkan suara mayoritas atau rata-rata [ 34 ].
Random Forest (RF): Ini adalah metode pembelajaran ensemble yang membangun beberapa DT menggunakan kumpulan data acak, sehingga mengurangi risiko overfitting dan meningkatkan akurasi prediksi. Algoritme ini menggabungkan hasil dari semua pohon, menggunakan pemungutan suara atau rata-rata, untuk memberikan keluaran yang konsisten dan akurat [ 35 ].
Extreme Gradient Boosting (XGBoost): Ini adalah kerangka kerja ML yang menggunakan pohon keputusan yang ditingkatkan gradien (GBDT) untuk memecahkan masalah regresi, klasifikasi, dan pemeringkatan. Ini dirancang agar dapat diskalakan. Ini memanfaatkan ansambel model yang lemah untuk membangun model yang kuat, sehingga mengurangi bias dan underfitting. XGBoost meningkatkan kinerja model dan meningkatkan kecepatan komputasi [ 36 ].
4.4 Metrik Kinerja
Kemanjuran metodologi yang disarankan dievaluasi dengan menggunakan ukuran seperti matriks kebingungan, akurasi, presisi, ingatan, dan skor F1 [ 37 ].
4.4.1 Matriks Kebingungan
Dengan menggunakan matriks kebingungan, para peneliti mengevaluasi kinerja metode klasifikasi. Tabel 2 mengilustrasikan contoh matriks kebingungan multikelas [ 38 ].
TABEL 2. Contoh representasi matriks kebingungan untuk kumpulan data multikelas.
| Diprediksi | ||||||
|---|---|---|---|---|---|---|
| Kelas 1 | Kelas 2 | Kelas 3 | Kelas 4 | Kelas 5 | ||
| Sebenarnya | Kelas 1 | TP1 | A12 | A13 | A14 | A15 |
| Kelas 2 | A21 | TP2 | A23 | A24 | A25 | |
| Kelas 3 | A31 | Pesawat A33 | TP3 | Pesawat A34 | Pesawat A35 | |
| Kelas 4 | A41 | A42 | Nomor A43 | TP4 | Pesawat A45 | |
| Kelas 5 | A51 | A52 | A53 | A54 | TP5 | |
4.4.2 Metrik
Metrik kinerja diilustrasikan dalam Tabel 3 .
TABEL 3. Metrik kinerja.
| Metrik | Keterangan | Persamaan |
|---|---|---|
| Ketepatan | Tingkat akurasi adalah rasio prediksi yang benar terhadap total prediksi yang dibuat oleh pengklasifikasi, yang menunjukkan efektivitasnya dalam memprediksi hasil di masa depan. | Accuracy=TP1+TP2+TP3+TP4∑iTPi+∑i,jAij |
| Presisi | Presisi adalah proporsi dari contoh-contoh yang diprediksi secara akurat dari suatu kelas tertentu terhadap semua contoh yang diantisipasi sebagai positif untuk kelas tersebut. | Precision=TPiTPi+FPi |
| Mengingat | Recall merupakan suatu ukuran kuantitatif yang menilai ketepatan estimasi kuantitas observasi nyata pada suatu kategori tertentu. | Recall=TPiTPi+FNi |
| Skor F1 | Skor F1 adalah metrik kuantitatif yang mengintegrasikan presisi dan ingatan model dengan menghitung rata-rata harmoniknya | F1−score=2×Precision×RecallPrecision+Recall |
| TPR | Nilai True Positive Rate menunjukkan seberapa baik model mengidentifikasi kasus positif |
5 Hasil dan Pembahasan
Bagian ini merinci hasil FDC: penulis menjelaskan cara mengoptimalkan hiperparameter beberapa model [ 39 ]. Setelah itu, mereka menunjukkan hasil terbaik dari set pelatihan untuk setiap model. Selain itu, mereka melakukan analisis komparatif dari semua model yang dibahas dalam karya ini. Terakhir, mereka menampilkan hasil model optimal yang beroperasi pada set data uji.
5.1 Penyetelan Hiperparameter
Berikut ini adalah hiperparameter untuk setiap model ML yang diadopsi dalam penelitian ini:
-
- Bahasa Indonesia:
○ n_estimators: Parameter ini menentukan jumlah pohon di hutan, yang secara langsung memengaruhi kinerja model dan efisiensi komputasi. Dalam studi ini, kami menguji tiga nilai:
- 5: Kelompok yang lebih kecil yang mungkin menghasilkan pelatihan yang lebih cepat tetapi kinerjanya berpotensi kurang kuat.
- 7: Kelompok menengah yang dapat menghasilkan latihan cepat dan performa tangguh.
- 10: Kumpulan yang lebih besar diharapkan dapat meningkatkan akurasi dan generalisasi model dengan menggabungkan prediksi dari lebih banyak pohon.
○
max_features: Parameter ini menentukan jumlah maksimum fitur yang dapat dipertimbangkan untuk dipisah di setiap node. Nilai yang diuji adalah:
- ‘otomatis’: Menggunakan akar kuadrat dari jumlah total fitur, yang membantu mengurangi overfitting.
- ‘sqrt’: Mirip dengan ‘auto’, pengaturan ini sering digunakan untuk tugas klasifikasi dan mendorong keberagaman di antara pohon.
○ max_depth: Parameter ini menetapkan kedalaman maksimum setiap pohon keputusan, yang mengendalikan kompleksitas model dan kedalaman pengambilan keputusan. Nilai yang diuji adalah:
- 10: Pohon yang lebih dangkal yang mungkin kurang sesuai dengan data, tetapi lebih kecil kemungkinannya untuk terlalu sesuai.
- 20: Pohon yang lebih dalam yang dapat menangkap pola yang lebih rumit tetapi berisiko melakukan overfitting pada data pelatihan.
○ bootstrap: Parameter ini menunjukkan apakah sampel bootstrap digunakan saat membangun pohon. Nilai pengujiannya adalah:
- ‘benar’: Sampel diambil dengan penggantian, meningkatkan ketahanan model.
- ‘salah’: Seluruh kumpulan data digunakan untuk membangun setiap pohon, yang dapat menyebabkan pengurangan varians tetapi dapat meningkatkan bias.
- XGBoost
○ max_depth: Parameter ini menentukan kedalaman maksimum pohon, yang memainkan peran penting dalam mengendalikan overfitting, dengan nilai-nilai berikut yang diuji:
- 7: Kedalaman sedang yang menyeimbangkan bias dan varians.
- 10: Kedalaman tinggi yang dapat menangani model yang kompleks.
- 20: Pohon yang lebih dalam yang dapat memodelkan hubungan yang lebih kompleks tetapi meningkatkan risiko overfitting.
○ min_child_weight: Parameter ini menentukan jumlah minimum bobot instans (hessian) yang diperlukan dalam simpul anak. Nilai yang diuji adalah:
- 1: Memungkinkan lebih banyak node untuk dipecah, berpotensi menangkap lebih banyak detail tetapi meningkatkan risiko overfitting.
- 6: Nilai yang lebih tinggi yang dapat mencegah model mempelajari pola yang terlalu spesifik, sehingga meningkatkan generalisasi.
- Tanggal:
○ Kriteria: Parameter ini mendefinisikan fungsi yang digunakan untuk mengukur kualitas split, dengan dua opsi yang didukung:
-
- Ketidakmurnian Gini: Suatu ukuran yang berfokus pada meminimalkan kemungkinan kesalahan klasifikasi.
- Entropi: Ukuran berdasarkan perolehan informasi, yang bertujuan untuk mengurangi ketidakpastian dalam kumpulan data.
○ min_samples_split: Parameter ini menunjukkan jumlah sampel minimum yang diperlukan untuk membagi node internal, dengan nilai yang diuji berkisar dari 1 hingga 20, yang memungkinkan optimalisasi kemampuan pohon untuk melakukan generalisasi sambil mengendalikan overfitting.
○
min_samples_leaf: Parameter ini menentukan jumlah sampel minimum yang diperlukan pada simpul daun, dengan nilai yang diuji berkisar antara 1 hingga 20, memastikan bahwa simpul daun memiliki jumlah sampel yang cukup untuk membuat prediksi yang andal.
- KNN
○ n_neighbors: Parameter ini menentukan jumlah tetangga yang perlu dipertimbangkan saat membuat prediksi, dengan nilai yang diuji sebesar 5, 10, dan 15, menyeimbangkan sensitivitas dan pengurangan kebisingan.
○
Bobot: Parameter ini menentukan bagaimana pengaruh tetangga dihitung selama prediksi, dengan opsi ‘seragam’ dan ‘jarak’, yang masing-masing melayani skenario yang berbeda.
Setelah menyetel setiap model dengan nilai hiperparameter yang sesuai, Tabel 4 mengilustrasikan nilai terbaik hiperparameter dari keempat model yang digunakan.
TABEL 4. Nilai Hiperparameter terbaik untuk empat model yang digunakan dalam makalah ini.
| frekuensi radio | XGBoost | Tanggal | KNN |
|---|---|---|---|
| n_estimator: 10
max_features: otomatis kedalaman_maks: 15 Bootstrap: Salah |
kedalaman_maks: 20
berat_anak_min: 1 |
min_sampel_terbagi: 10
min_sampel_daun: 5 Kriteria: entropi |
n_tetangga: 10
Berat: Jarak |
Bahasa Indonesia: Saat menggunakan model RF, pengaturan optimal mencakup 10 estimator, Pemilihan fitur otomatis (max_features: auto), Kedalaman maksimum 10, dan tidak ada pengambilan sampel bootstrap. Parameter ini menghasilkan keseimbangan sempurna antara bias dan varians, yang memungkinkan model untuk menangkap kompleksitas data tanpa overfitting. Model XGBoost memberikan kinerja luar biasa dengan Kedalaman maksimum 20 dan, Bobot anak minimum 1. Pengaturan ini memungkinkan model untuk menangani pohon yang lebih dalam secara efektif, memastikan pemisahan hanya terjadi ketika ada cukup observasi untuk membenarkannya. Ini meningkatkan kemampuan model untuk menangkap hubungan non-linier dalam data. Untuk model DT, pengaturan yang dipilih adalah: Sampel minimum untuk membagi node sama dengan 10, Sampel daun minimum 5, dan Kriteria untuk pemisahan: entropi. Konfigurasi ini menekankan preferensi untuk proses pengambilan keputusan yang kuat, mengurangi risiko overfitting dengan menuntut lebih banyak sampel untuk pemisahan dan menjamin bahwa node daun berisi banyak data.
5.2 Hasil dan Pembahasan
Matriks kebingungan untuk 16 kelas berbeda yang dihasilkan oleh model ML yang dieksplorasi dalam penelitian ini setelah diterapkan pada set pelatihan ditampilkan dalam Gambar 5 , Gambar 6 , Gambar 7 , dan Gambar 8. Selain itu, Tabel 5 menampilkan metrik kinerja dari empat model ML pada set pelatihan. Seperti yang diilustrasikan dalam tabel ini, model XGBoost mencapai akurasi tertinggi pada 99,98% dan menunjukkan presisi, perolehan, dan skor F1 yang luar biasa, sehingga membuatnya sangat andal untuk deteksi kesalahan waktu nyata dalam sistem PV. Sebaliknya, model RF berkinerja baik dengan akurasi 99,86% dan kinerja keseluruhan yang kuat. Model Decision Tree menunjukkan akurasi yang lumayan sebesar 97,30% dan tetap menguntungkan untuk aplikasi yang memerlukan proses pengambilan keputusan yang jelas. Sebaliknya, model KNN berkinerja buruk dengan akurasi 75,60% dan mungkin memerlukan penyetelan lebih lanjut untuk aplikasi khusus ini. Singkatnya, metode ensemble, khususnya XGBoost, mengungguli model lain untuk deteksi kesalahan pada sistem PV, menyoroti keunggulannya untuk aplikasi berisiko tinggi.

GAMBAR 5

GAMBAR 6

GAMBAR 7

GAMBAR 8
| Model | Akurasi (%) | Presisi makro | Presisi mikro | Penarikan kembali makro | Ingatan mikro | Skor Makro F1 | Skor Mikro F1 |
|---|---|---|---|---|---|---|---|
| frekuensi radio | 99.86 | 0,990 | 0,999 | 0,988 | 0,990 | 0,989 | 0,990 |
| KNN | 75.60 | 0.781 | 0.756 | 0.756 | 0.756 | 0.757 | 0.756 |
| Tanggal | 97.30 | 0,973 tahun | 0,973 tahun | 0,973 tahun | 0,973 tahun | 0,973 tahun | 0,973 tahun |
| XGBoost | 99,98 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 |
CM biner untuk 16 kelas digambarkan pada Gambar 9 , 10 , dan 11 .
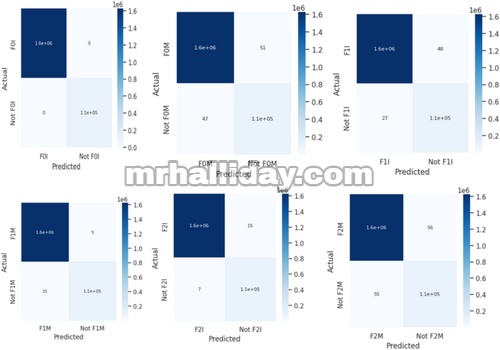
GAMBAR 9
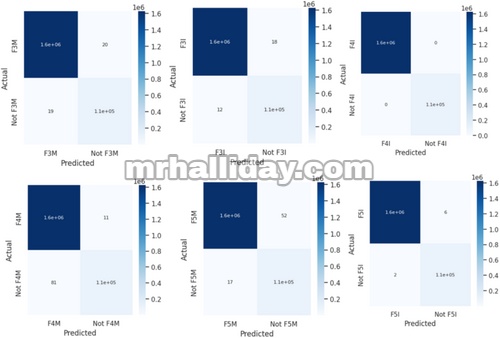
GAMBAR 10

GAMBAR 11
Oleh karena itu, akurasi, presisi, recall, dan skor F1 setiap kelas ditentukan dan disajikan dalam Tabel 6 .
TABEL 6. Akurasi, presisi, ingatan, dan skor f1 dari 16 kelas dalam mode MPPT dan IPPT.
| Metrik | Informasi | F0M | F1I | F1M | F2I | F2M | F3I | F3M |
|---|---|---|---|---|---|---|---|---|
| Ketepatan | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| Presisi | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| Mengingat | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| Skor F1 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| TPR | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 | 0,999 |
| FPR(%) | angka 0 | 0.2 | 0.4 | angka 0 | angka 0 | 0.4 | 0.5 | angka 0 |
| Metrik | F4I | F4M | F5I | F5M | F6I | F6M | F7I | F7M |
|---|---|---|---|---|---|---|---|---|
| Ketepatan | 0,999 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 |
| Presisi | 0,999 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 |
| Mengingat | 0,999 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| Skor F1 | 0,999 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| TPR | 0,999 | 1.000 | 0,999 | 0,999 | 0,999 | 0,999 | 0,999 | 1.000 |
| FPR (%) | 0.1 | angka 0 | angka 0 | angka 0 | 0.3 | angka 0 | angka 0 | 0.2 |
Seperti yang ditunjukkan pada Tabel 6 , FDC menunjukkan kinerja luar biasa dalam mengidentifikasi dan mengklasifikasikan kesalahan secara akurat di 16 kelas di bawah mode MPPT dan IPPT, sebagai berikut:
- Ia mencapai skor akurasi sempurna sebesar 1.000 untuk beberapa kelas dan mempertahankan akurasi yang sangat tinggi (sekitar 0,999) untuk kelas lainnya, yang menunjukkan kemampuan deteksi kesalahan yang tangguh.
- Nilai presisi sebagian besar mencerminkan hasil ini, dengan sebagian besar kelas mencapai skor 1.000, meminimalkan positif palsu dan memperkuat keandalan model.
- Metrik penarikan kembali juga menunjukkan skor tinggi (1,000 dan 0,999), yang mencerminkan efektivitas model dalam mengenali hampir semua kesalahan aktual.
- Skor F1 secara konsisten tetap tinggi, menunjukkan kinerja yang seimbang antara presisi dan ingatan.
- Secara keseluruhan, hasil ini menegaskan kesesuaian model untuk aplikasi fotovoltaik di dunia nyata, memastikan pemantauan yang efektif dan respons kesalahan yang cepat.
Selain itu, nilai TPR menunjukkan seberapa baik model deteksi kesalahan dapat mengidentifikasi masalah dalam sistem PV surya secara akurat. Sebagian besar metrik menunjukkan sensitivitas tinggi sebesar 0,999, dengan beberapa mencapai skor sempurna sebesar 1.000. Tingkat kinerja yang tinggi ini sangat penting dalam konteks energi surya, karena kegagalan dalam mendeteksi kesalahan dapat mengakibatkan hilangnya energi secara signifikan dan peningkatan biaya perawatan.
FPR untuk FDC dalam sistem PV surya umumnya sangat rendah, dengan sebagian besar metrik melaporkan FPR pada atau mendekati 0%. Hal ini penting untuk menghindari inspeksi dan pemeliharaan yang tidak perlu, yang dapat mengakibatkan peningkatan biaya operasional. Namun, jenis gangguan tertentu, khususnya F1M dan F3I, memiliki FPR yang sedikit lebih tinggi, masing-masing sebesar 0,4% dan 0,5%. Gangguan ini menghadapi tantangan dalam membedakan antara variasi operasional normal dan gangguan aktual.
Sebanyak 10.000 iterasi bootstrap dilakukan dengan mengambil sampel acak nilai akurasi dengan penggantian untuk menghasilkan berbagai distribusi metrik akurasi. Kemudian, nilai tengah dihitung dari sampel bootstrap, dan persentil ke-2,5 dan ke-97,5 ditentukan untuk menetapkan interval keyakinan 95%. Analisis mengungkapkan bahwa interval keyakinan terkecil untuk akurasi model XGBoost adalah (99,92%, 100,00%), yang menunjukkan keyakinan 95% bahwa akurasi sebenarnya dari model berada dalam rentang ini.
5.3 Diskusi
Tabel 5 menunjukkan bahwa XGBoost mengungguli model lain dalam hal akurasi, presisi, recall, dan skor F1. Oleh karena itu, model ini dipilih sebagai model optimal untuk mengidentifikasi masalah dalam sistem PV dan mengkategorikan kesalahan tersebut.
KNN dan DT merupakan model yang paling tidak efektif untuk mengklasifikasikan jenis kesalahan dalam sistem PV. Secara khusus, KNN memiliki tingkat akurasi yang rendah, seperti yang ditunjukkan dalam Tabel 5. Meskipun demikian, model RF dan XGBoost menunjukkan kinerja yang unggul dalam mendeteksi jenis kesalahan secara akurat. Lebih jauh lagi, presisinya sangat tinggi, sebagaimana dibuktikan oleh data yang disajikan dalam Tabel 4. Pembelajaran ensemble lebih efektif dalam mendeteksi dan mengkategorikan cacat dalam sistem PV.
Tabel 6 menunjukkan kinerja XGboost yang unggul setelah mengoptimalkan parameter dalam mengidentifikasi dan mengkategorikan jenis kesalahan dalam sistem PV. Jenis kesalahan F4M diklasifikasikan dengan akurasi, daya ingat, dan presisi 100%. Lebih jauh, masalah yang tersisa diidentifikasi dengan tingkat akurasi, presisi, dan daya ingat 99%.
Hasil penelitian ini melampaui hasil yang diperoleh Zaki et al. [ 19 ], ketika para ilmuwan hanya memeriksa kasus normal dan enam cacat. Mereka mendiagnosis kasus normal dengan tingkat akurasi 100%, sedangkan akurasi mendeteksi kesalahan berkisar antara 97% dan 100%.
5.4 Perbandingan
Setelah meneliti hasil yang diperoleh dalam makalah penelitian ini, penting untuk memeriksa kemajuan karya ini dibandingkan dengan karya sebelumnya dalam literatur. Dengan demikian, Tabel 7 merangkum perbandingan model yang diusulkan dalam makalah ini dengan model pendekatan sebelumnya dalam literatur.
TABEL 7. Perbandingan hasil penelitian ini dengan hasil yang ada di literatur.
| Artikel | Kelas sasaran | Teknik ML | Akurasi (%) |
|---|---|---|---|
| Zaki dan kawan-kawan. [ 19 ] | Jenis kesalahan normal vs. enam jenis kesalahan | KNN | 97.00 |
| frekuensi radio | 97.90 | ||
| KERANJANG | 97.86 | ||
| Chokr dan kawan-kawan. [ 21 ] | Jenis kesalahan normal vs. enam jenis kesalahan | LGBT | 99.70 |
| KucingPendorong | 99.50 | ||
| XGBoost | 99.30 | ||
| Adhya dan kawan-kawan. [ 22 ] | Lima jenis kesalahan | Catatan | 67.80 |
| Tanggal | 73.90 | ||
| Bahasa Indonesia: SVM | 70.43 | ||
| frekuensi radio | 79.13 | ||
| KNN | 69.53 | ||
| JAM | 80.86 | ||
| Mellit dan Kalogirou [ 24 ] | Tiga jenis kesalahan | DAFTAR BIASA | 99,98 |
| Mustafa dan kawan-kawan. [ 23 ] | Jenis normal dan enam jenis kesalahan | Berita CNN | 98.50 |
| FDC | Mode normal di bawah MPPT | KNN | 75.60 |
| Model normal di bawah IPPT | Tanggal | 97.32 | |
| Tujuh jenis kesalahan dalam MPPT | frekuensi radio | 99.86 | |
| Tujuh jenis kesalahan dalam IPPT | XGBoost | 99,98 |
Seperti yang ditunjukkan pada Tabel 7 , metode FDC memiliki jumlah kesalahan yang lebih tinggi di bawah dua mode fungsionalitas yang berbeda. Ini juga menunjukkan akurasi yang lebih tinggi sebesar 99,98%. Akurasi ini sebanding dengan pekerjaan yang disajikan oleh Mellit dan Kalogirou [ 24 ]. Namun, Mellit hanya mencakup tiga jenis kesalahan. Selain itu, metode FDC dengan KNN menunjukkan akurasi yang lebih tinggi daripada KNN yang diusulkan dalam Adhya et al. [ 22 ]. Peningkatan ini dikaitkan dengan langkah penyetelan hiperparameter yang dilakukan dalam pendekatan FDC. Lebih jauh lagi, FDC mengungguli metode yang disajikan dalam Bakdi et al. [ 28 ] yang menggunakan kumpulan data yang sama, mencapai FDR kurang dari 0,4% menunjukkan presisi yang lebih tinggi dalam kemampuan deteksi kesalahannya. Peningkatan kinerja ini dapat secara signifikan mengurangi beban operasional yang terkait dengan positif palsu, memastikan bahwa tim pemeliharaan tidak kewalahan dengan peringatan yang tidak memerlukan tindakan.
6 Kesimpulan
Untuk mencegah gangguan daya yang tidak terduga, sangat penting untuk menggunakan metode yang cepat dan efisien untuk mendeteksi dan mendiagnosis kesalahan. Makalah ini menyajikan pendekatan prospektif (disebut FDC) untuk mendeteksi dan mengklasifikasikan kesalahan menggunakan ML. Pemeriksaan tersebut mencakup kategori kesalahan normal dan tujuh kategori kesalahan spesifik. Lebih jauh, penulis penelitian ini menganalisis dua mode operasi yang berbeda: pelacakan titik daya maksimum dan pelacakan titik daya menengah. Dengan demikian, 16 kelas diidentifikasi dan diklasifikasikan dalam penelitian ini. Penulis pertama-tama mengumpulkan dan menggabungkan data dari berbagai berkas. Setelah itu, langkah-langkah praproses diterapkan untuk menghapus data yang tidak diinginkan dan menangani masalah ketidakseimbangan. Kemudian, mereka menilai empat algoritme ML yang berbeda dan teknik pembelajaran ensemble untuk mengidentifikasi model yang optimal. Teknik validasi silang diterapkan untuk mengendalikan overfitting, yang dapat terjadi ketika suatu model dilatih terlalu baik pada data pelatihan dan berkinerja buruk pada data baru. Selain itu, mereka melakukan pengujian dan validasi model yang ketat, menggunakan beragam kriteria dan fitur untuk memastikan konfigurasi yang paling optimal untuk setiap model. Metode FDC beroperasi secara independen dari kondisi lingkungan. Ia hanya mengandalkan parameter arus dan tegangan dari sistem PV surya. Mudah diimplementasikan secara real-time menggunakan teknik pembelajaran mesin dasar, bukan jaringan saraf yang kompleks. Selain itu, ia cukup serbaguna untuk mendeteksi 16 mode operasional sistem PV surya yang berbeda. Hasil eksperimen menunjukkan bahwa teknik pembelajaran ensemble lebih efektif daripada metode tradisional dalam mendeteksi dan mengkategorikan masalah dalam sistem surya. XGBoost, setelah mengoptimalkan parameter, berhasil mengidentifikasi dan mengkategorikan jenis kesalahan dalam sistem PV dengan akurasi yang setara dengan 99,98%. Selain itu, presisi dan perolehan kembali dalam mendeteksi beberapa default sama dengan 100%. Lebih jauh, masalah yang tersisa diidentifikasi dengan tingkat akurasi, presisi, dan perolehan kembali 99%. Nilai TPR menunjukkan seberapa baik model deteksi kesalahan dapat secara akurat mengidentifikasi masalah dalam sistem PV surya. Sebagian besar metrik menunjukkan sensitivitas tinggi sebesar 0,999, dengan beberapa mencapai skor sempurna sebesar 1.000. Kinerja ini sangat penting dalam konteks energi surya, karena kegagalan dalam mendeteksi kesalahan dapat mengakibatkan kehilangan energi yang signifikan dan peningkatan biaya perawatan. FPR untuk FDC dalam sistem PV surya umumnya sangat rendah, dengan sebagian besar metrik melaporkan FPR pada atau mendekati 0%. Beberapa jenis kesalahan, seperti F1M dan F3I, menunjukkan FPR yang sedikit lebih tinggi, masing-masing sebesar 0,4% dan 0,5%, dan menghadapi tantangan dalam membedakan antara variasi operasional normal dan kesalahan aktual.
Langkah berikutnya dalam penelitian ini adalah menggunakan pendekatan FDC pada sistem PV surya aktual untuk memvalidasi kemanjurannya di berbagai konteks operasional. Kami melakukan eksperimen lapangan yang komprehensif di berbagai wilayah geografis dan kondisi meteorologi untuk mengevaluasi ketahanan dan kemampuan beradaptasi metode tersebut. Lebih jauh lagi, penggunaan metodologi pembelajaran mesin yang canggih, seperti pembelajaran mendalam dan model hibrida, dapat meningkatkan presisi deteksi kesalahan dan menangani kategori kesalahan yang lebih rumit. Menambah kumpulan data untuk mencakup spektrum yang lebih luas dari status kesalahan dan skenario pengoperasian meningkatkan generalisasi model. Penulis akan mengembangkan antarmuka intuitif untuk pemantauan dan diagnostik waktu nyata, yang akan membantu operator menerapkan temuan ini secara efektif dalam konteks praktis.